|
Power Fractal Software
High-performance parallel software utilizing:
|
AltiVec, a.k.a. the Velocity Engine |
Multiprocessing ("MP") and multi-Core |
|
SSE & SSE2 |
Universal (Intel & PowerPC) |
|
MPI over TCP/IP, via MacMPI_XUB |
Carbon (OS 9 & X) |
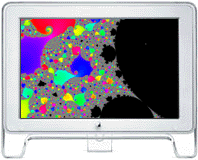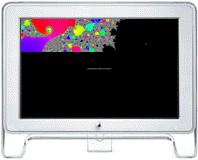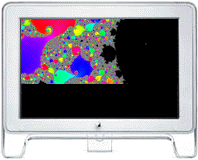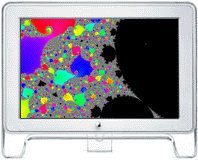
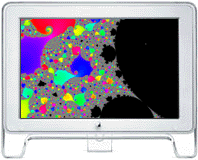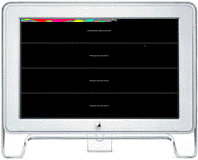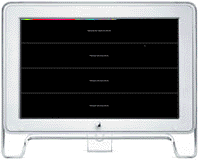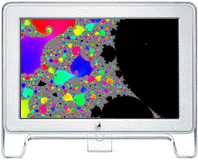
Single Node Performance of the Power Fractal app
4-Node Parallel Performance of the Power Fractal app using Pooch
|
|
 Power Fractal v1.4.1 (160 kB) -
A numerically-intensive parallel graphics application that
uses the vector hardware, multiple processors or Cores (MP), and cluster computing (via MPI)
for its computations.
Power Fractal takes simultaneously advantage of both the Velocity Engine, a.k.a. AltiVec,
and SSE, when available.
This code will also compute correctly on single processor machines and non-vector processors.
This code uses the MacMPI_XUB.c library for communcations and and requires Mac OS X 10.3.9 or later
and Pooch.
Power Fractal v1.4.1 (160 kB) -
A numerically-intensive parallel graphics application that
uses the vector hardware, multiple processors or Cores (MP), and cluster computing (via MPI)
for its computations.
Power Fractal takes simultaneously advantage of both the Velocity Engine, a.k.a. AltiVec,
and SSE, when available.
This code will also compute correctly on single processor machines and non-vector processors.
This code uses the MacMPI_XUB.c library for communcations and and requires Mac OS X 10.3.9 or later
and Pooch.
|
New in version 1.4.1: Newly reoptimized SSE code and fractal presets
for the new 8-Core Mac Pro, where it can achieve over 80 GigaFlops.
Thanks xlr8yourmac!
New in version 1.4:
As a Universal Application,
this code can utilitze large, mixed clusters of PowerPC G3s, G4s, G5s
and Intel Cores simultaneously,
making this the first application to utilize Universal Clustering.
(Requires Pooch v1.7.)
See the the DR product line
for more examples.
|
|

|
We also provide a
Carbon CFM version of Power Fractal that requires Mac OS 10.2 or later, or
Mac OS 8.5 or later
with CarbonLib 1.2 or later,
New in version 1.3:
This app's parallelization organization has been rewritten to be optimized for large clusters of PowerPC G5s,
enabling it to achieve over 1.21 TeraFlop!
This code has achieved:
Your results may vary. Click on the above links for benchmark
information.
|
To run this app on a single Intel- or PowerPC-based Mac, no
additional software is necessary.
To run this in parallel on Intel and PowerPC Macs, you will need
Pooch.
Version 1.1 includes automated "Computational Grid" launching
on a Mac cluster running version
1.1 of Pooch.
See
the
Pooch Quick Start for instructions on configuring your Macs for parallel computing.
For information about writing your own parallel applications, see
the Parallel Fractal GPL source code,
the Cluster Software Development Kit, and
the Compiling MPI page.
Behind the Scenes
What the
AltiVec source code of Power Fractal looks like
The Power Fractal app contains code for both the z -> z^2 + c
and z -> z^4 + c Mandelbrot-style iteration methods. Although the z^4 case is
selected by default, the z^2 case is shown below for simplicity.
The innermost loop of the iteration for the regular FPU case is:
//12 flops per iteration (counted in the assembly language)
{
float tr;
count++;
tr=ca+za*za-zb*zb;
zb=cb+zb*za+zb*za;
za=tr;
tr=tr*tr+zb*zb;
if
(tr>sqrmaxrad) {
}
}
|
To rewrite the above code for AltiVec, the multiplications, additions, and
subtractions must be reexpressed in AltiVec macros, such as vec_madd and
vec_nmsub. The comparison operations must be performed in vector form as well,
here using vec_cmpgt, vec_and, and vec_any_ne. Note that there is no such thing
as a simple floating-point multiply in AltiVec; you must add to something
after the multiply. Thus an add to zero is required to complete the iteration
loop.
The corresponding loop, converted to AltiVec is:
//13 flops - 1 add to zero = 12 flops per iteration
{
vector float tr;
count++;
tr=vec_madd(za,za,vec_nmsub(zb,zb,ca));
zb=vec_madd(zb,za,vec_madd(zb,za,cb));
za=tr;
tr=vec_madd(zb,zb,vec_madd(tr,tr,zero));
{
vector bool int
exitMask=vec_and(vec_cmpgt(tr, sqrmaxrad),loopMask);
if
(vec_any_ne(exitMask,zeroInt)) {
}
}
}
|
This is the primary difference between the AltiVec and non-AltiVec version of
the z^2 code. The remaining differences involve preparing the vector variables
with the appropriate data prior to the iteration loop and saving the final data
out into a regular array of floating-point numbers for later conversion to pixel
data.
For a slightly more complex example of vectorized code, compare sections of
the DoSqueezeToLetterboxEffect()
routine in the
source code of
the iMovie Squeeze to Letterbox plug-in on
the Other Software page.
|
|