|
Parallelization - Parallel Pascal's Triangle
|
We describe the conversion of a single-processor propagation-style code into a parallel code.
This example demonstrates how one might handle a system whose partitions are not independent of
one another, but have localized interactions.
A simple "divide and conquer" approach is insufficient because of the interdependencies
in the system.
Nonetheless, the work of the code can be partitioned between the processors with their dependencies
handled efficiently.
|
|
This technique applies to a variety of possible codes. Problems that can be translated into
finite difference equations, which include the diffusion equation, wave propagation, fluid dynamics, or
other problems described by partial differential equations, have an almost direct correspondence to the
components of this code.
In the two-dimensional graphics space, filters such as Gaussian blur, sharpen, or other convolution-style
algorithms also can be thought of as
a propagation of information from one pixel to its neighbors, i. e., a local interaction.
Also, portions of a code could be similar to those problems, making this technique applicable.
Other more complex codes such as particle-based simulations, including the particle push of most plasma PIC codes,
molecular dynamics codes,
or
astronomical or other N-body simulations, could benefit from the parallelization approach demonstrated here.
Finally, if you are learning about parallel code,
the following builds on how to combine partitioning with elemental message-passing
when writing and thinking about parallel codes.
|
Before: Single-Processor pascalstriangle
This single-processor example, pascalstriangle,
performs a direct computation of Pascal's triangle.
The algorithm is as follows: Begin with a row of integers.
Compute the next row of integers by adding pairs, in order, of immediately neighboring integers of the previous row.
Continue until the desired height of the triangle, or length of propagation, is reached.
An interesting property of this computation is that if the initial row contains only zeros except for a one in the middle
of the row, the subsequent values will be the coefficients of the finite binomial series: (1 + x)^n for each power of x.
Each successive row of integers will correspond to the coefficients resulting from (1 + x)^n for higher
powers of n.
Although the binomial series does have a closed-form solution, pascalstriangle performs the
direct computation so that one could experiment different seed integers, i.e., different initial conditions,
or different rules at the end of finite integer rows, i.e., boundary conditions,
and view the interaction and evolution.
|

|
This code is organized into three routines:
- addright and addleft - performs the work of adding neighboring elements of an array,
returning its output in the same array to save on memory allocation and accesses. Alternating calls to
addright and addleft
obviates potentially costly memory moves or copies.
- iterationloop - performs the propagation loop for a specified number of iterations,
alternating calls between addright and addleft, and reports desired diagnostics
- computeloop - allocates memory, initializes and seeds the system,
calls iterationloop, and returns the final state of the system
- main - calls computeloop, saves its results into a file, printf's the final system state, and deallocates memory
The code is structured to clearly identify the sections that perform work primary to the problem
and parts secondary to the problem yet required to complete the work.
These include
allocating the appropriate memory and saving data to an output file.
Besides identifying where these functions are being performed,
the structure makes it obvious where to substitute this code's propagation rule.
The C source is shown in Listing 1.
Listing 1 - pascalstriangle.c
See also pascalstriangle.f90
#include <stdio.h> /* standard I/O routines */
#include <stdlib.h> /* standard library routines, such as memory */
#include <math.h> /* math libraries */
#define myType unsigned long
/* Routines performing elemental work. */
void addright(myType *inputArray, long size);
void addright(myType *inputArray, long size)
{
if (inputArray) {
long i=size-1;
while (i--)
inputArray[i+1]+=inputArray[i];
}
}
void addleft(myType *inputArray, long size);
void addleft(myType *inputArray, long size)
{
if (inputArray) {
long i;
for(i=0; i<size-1; i++)
inputArray[i]+=inputArray[i+1];
}
}
void iterationloop(myType *theArray, long arraySize, long lastIteration, short verbose);
void iterationloop(myType *theArray, long arraySize, long lastIteration, short verbose)
{
if (theArray) if (arraySize>0) {
long index;
/* loop over indicies */
for(index=0; index<lastIteration; index++) {
/* call the left or right routine for each index, reusing array */
if (1&index) {
addleft(theArray, arraySize);
}
else {
addright(theArray, arraySize);
}
if (verbose) {long i;
for(i=0; i<arraySize; i++) {
if (1&verbose)
printf("%d\t", theArray[i]);
else
printf("%c", theArray[i]&1?'*':' ');
}
printf("\n");
}
}
}
}
/* BinomialExponent specifies how far to propagate */
void computeloop(myType **theArray, long binomalExponent);
void computeloop(myType **theArray, long binomalExponent)
{
/* local copies of the data to be output */
myType *myArray;
long arraySize=binomalExponent+1;
/* allocate an array to hold all the results */
myArray=malloc(sizeof(myType)*arraySize);
if (myArray) {
long i;
/* clear the array */
for(i=arraySize; i--; )
myArray[i]=0;
/* seed the array */
myArray[binomalExponent>>1]=1;
/* propagate */
iterationloop(myArray, arraySize, binomalExponent, 2);
}
/* return the array */
*theArray=myArray;
}
#define BinomialExponent 30L
int main(int argc, char *argv[])
{
/* main copies of the sum and the array */
myType *theArray=NULL;
printf("Beginning computation...\n");
computeloop(&theArray, BinomialExponent);
if (theArray) {/* error checking */
FILE *fp;
/* save the array into a data file */
fp=fopen("output", "w");
if (fp) {
printf("writing array...\n");
fwrite(theArray, sizeof(myType), BinomialExponent+1, fp);
fclose(fp);
}
if (1) {long i;
for(i=0; i<BinomialExponent+1; i++)
printf("%d\t", theArray[i]);
printf("\n");
}
/* clean up after myself */
free(theArray);
}
else
printf("memory allocation failure\n");
return 0;
}
|
|
When this code is run with its BinomialExponent constant set to 30 and the default seed, the code produces this output:
Beginning computation...
**
* *
****
* *
** **
* * * *
********
* *
** **
* * * *
**** ****
* * * *
** ** ** **
* * * * * * * *
****************
* *
** **
* * * *
**** ****
* * * *
** ** ** **
* * * * * * * *
******** ********
* * * *
** ** ** **
* * * * * * * *
**** **** **** ****
* * * * * * * *
** ** ** ** ** ** ** **
* * * * * * * * * * * * * * * *
writing array...
1 30 435 4060 27405 142506 593775 2035800 5852925 14307150 30045015 54627300 86493225 119759850 145422675 155117520 145422675 119759850 86493225 54627300 30045015 14307150 5852925 2035800 593775 142506 27405 4060 435 30 1
|
Note the shape formed by the asterisks. Those asterisks denote which integers were odd, set by the verbose flag passed to
iterationloop. The shape is a Sierpinski gasket, which is known to be produced by Pascal's triangle.
You can try changing the seed line of integers to see how these patterns interact or try changing the test
in iterationloop for printing the asterisks (e.g., to &2 or &4).
|
After: parallelpascalstriangle
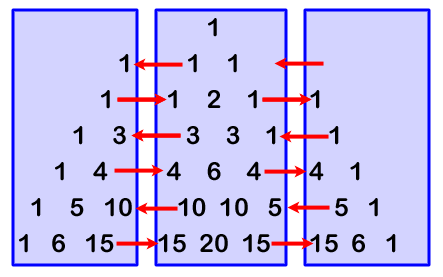
Choosing the appropriate partitioning of the problem is key to parallelizing that application.
The decision made here is to evenly divide the row of integers into one block per processor.
An important detail is that the trailing edge of one block will influence the leading edge of the next,
a result of the nature of the interdependence in this system: interactions are localized.
The parallelization process begins with managing and delegating data and computation with an additional step
to propagate interactions between processors.
Changes to main are limited to "boilerplate" code that start up and shut down the parallel environment and
pass the sufficient information to computeloop so that it can organize the work, with a
if test so only processor 0 creates an output file.
|

|
The modifications in computeloop calculate the partitioning between
processors. Given the identification number of the processor it is running on and the number of
processors in the system, computeloop calculates how to partition the problem among the processors.
To minimize bottlenecks, the executable running on each processor calculates its assignment itself, without a central
authority delegating assignments.
|
The modifications to iterationloop perform the propagation between
edges of the problem space assigned to each processor.
computeloop supplies the information needed to perform this interaction in addition to the
arrays that hold the system to be propagated and the size of the problem.
A subtle point is that computeloop supplies one extra element to iterationloop
so that it has room for an extra element duplicating the closest element neighboring processor.
Interprocessor communication during the primary computation
reduces to maintaining these duplicate elements at the appropriate points in the parallel code.
Once it finishes its work, computeloop collects the data back to processor 0 so main can
write the output in one place convenient for the user.
|
|
The detailed answer is in the code.
Listing 2 shows the C source of parallelpascalstriangle, with the changes relative to pascalstriangle underlined.
Listing 2 - parallelpascalstriangle.c, with changes compared to pascalstriangle.c underlined
See also parallelpascalstriangle.f90
#include /* standard I/O routines */
#include /* standard library routines, such as memory */
#include /* math libraries */
#include "mpi.h" /* MPI library */
#define myType unsigned long
/* Routines performing elemental work. */
void addright(myType *inputArray, long size);
void addright(myType *inputArray, long size)
{
if (inputArray) {
long i=size-1;
while (i--)
inputArray[i+1]+=inputArray[i];
}
}
void addleft(myType *inputArray, long size);
void addleft(myType *inputArray, long size)
{
if (inputArray) {
long i;
for(i=0; i<size-1; i++)
inputArray[i]+=inputArray[i+1];
}
}
void iterationloop(myType *theArray, long arraySize, long lastIteration,
short verbose, int idproc, int nproc);
void iterationloop(myType *theArray, long arraySize, long lastIteration,
short verbose, int idproc, int nproc)
{
if (theArray) if (arraySize>0) {
long index;
long leftIDProc=idproc-1, rightIDProc=idproc+1;
MPI_Request request; MPI_Status status;
/* get to know my (processor's) neighbors */
if (leftIDProc<0)
leftIDProc=nproc-1;
if (rightIDProc>=nproc)
rightIDProc=0;
/* loop over indicies */
for(index=0; index<lastIteration; index++) {
/* call the left or right routine for each index,
reusing array */
if (1&index) {
addleft(theArray, arraySize);
MPI_Irecv(&theArray[arraySize-1], 1, MPI_LONG,
rightIDProc, index, MPI_COMM_WORLD, &request);
MPI_Send(&theArray[0], 1, MPI_LONG,
leftIDProc, index, MPI_COMM_WORLD);
MPI_Wait(&request, &status);
}
else {
addright(theArray, arraySize);
MPI_Irecv(&theArray[0], 1, MPI_LONG,
leftIDProc, index, MPI_COMM_WORLD, &request);
MPI_Send(&theArray[arraySize-1], 1, MPI_LONG,
rightIDProc, index, MPI_COMM_WORLD);
MPI_Wait(&request, &status);
}
if (verbose) {long i;
for(i=0; i<arraySize; i++) {
if (1&verbose)
printf("%d\t", theArray[i]);
else
printf("%c", theArray[i]&1?'*':' ');
}
printf("\n");
}
}
}
}
void computeloop(myType **theArray, long binomialExponent, int idproc, int nproc);
void computeloop(myType **theArray, long binomialExponent, int idproc, int nproc)
{
myType *myArray;
long arraySize=((binomialExponent+nproc)/nproc)+1;
/* allocate an array to hold all the results */
myArray=malloc(sizeof(myType)*(idproc?arraySize:binomialExponent+nproc));
if (myArray) {
long i;
/* clear the array */
for(i=arraySize; i--; )
myArray[i]=0;
/* seed the array */
if (idproc==((binomialExponent>>1)/(arraySize-1)))
myArray[(binomialExponent>>1)-idproc*(arraySize-1)]=1;
/* propagate */
iterationloop(myArray, arraySize, binomialExponent, 2, idproc, nproc);
/* proc 0's has a bigger array so we can gather all the data at the end */
{myType *bigArray=idproc?NULL:malloc(sizeof(myType)*(binomialExponent+nproc));
/* gathers the data from the other arrays ... */
MPI_Gather(myArray, arraySize-1, MPI_LONG,
bigArray, arraySize-1, MPI_LONG,
/* ... to proc 0 */ 0, MPI_COMM_WORLD);
if (!idproc) {
free(myArray);
myArray=bigArray;
}
}
}
/* return the array */
*theArray=myArray;
}
int ppinit(int argc, char *argv[], int *idproc, int *nproc);
void ppexit(void);
/* BinomialExponent specifies how far to propagate */
#define BinomialExponent 30L
int main(int argc, char *argv[])
{
/* main copies of the sum and the array */
myType *theArray=NULL;
int idproc, nproc, ierr;
/* initialize parallel processing */
ierr = ppinit(argc, argv, &idproc, &nproc);
if (ierr) return ierr; /* stop right there if there's a problem */
printf("I'm processor #%d in a %d-processor cluster.\n", idproc, nproc);
printf("Beginning computation...\n");
computeloop(&theArray, BinomialExponent, idproc, nproc);
if (theArray) {/* error checking */
if (!idproc) {/* only processor 0 */
FILE *fp;
/* save the array into a data file */
fp=fopen("output", "w");
if (fp) {
printf("writing array...\n");
fwrite(theArray, sizeof(myType), BinomialExponent+1, fp);
fclose(fp);
}
}
if (1) {long i;
for(i=0; i<BinomialExponent+1; i++)
printf("%d\t", theArray[i]);
printf("\n");
}
/* clean up after myself */
free(theArray);
}
else
printf("memory allocation failure\n");
/* only proc 0 pauses for user exit */
if (!idproc) {
printf("press return to continue\n");
getc(stdin);
}
ppexit();
return 0;
}
#ifdef __MWERKS__
/* only for Metrowerks CodeWarrior */
#include <SIOUX.h>
#endif
int ppinit(int argc, char *argv[], int *idproc, int *nproc)
{
/* this subroutine initializes parallel processing
idproc = processor id
nproc = number of real or virtual processors obtained */
int ierr;
*nproc=0;
/* initialize the MPI execution environment */
ierr = MPI_Init(&argc, &argv);
if (!ierr) {
/* determine the rank of the calling process in the communicator */
ierr = MPI_Comm_rank(MPI_COMM_WORLD, idproc);
/* determine the size of the group associated with the communicator */
ierr = MPI_Comm_size(MPI_COMM_WORLD, nproc);
#ifdef __MWERKS__
/* only for Metrowerks CodeWarrior */
SIOUXSettings.asktosaveonclose=0;
SIOUXSettings.autocloseonquit=1;
#endif
}
return ierr;
}
void ppexit(void)
{
/* this subroutine terminates parallel processing */
int ierr;
/* waits until everybody gets here */
ierr = MPI_Barrier(MPI_COMM_WORLD);
/* terminate MPI execution environment */
ierr = MPI_Finalize();
}
|
|
The changes from pascalstriangle to parallelpascalstriangle:
- mpi.h - the header file for the MPI library, required to access information about the parallel system and perform communication
- idproc, nproc -
nproc describes how many processors are currently running this job and
idproc identifies the designation, labeled from 0 to nproc - 1, of this processor.
This information is sufficient to identify exactly which part of the problem this instance of the executable should work on.
In this case, these variables are supplied to computeloop by main
and to iterationloop by computeloop.
- leftIDProc and rightIDProc -
this variables describe the designated processor id's of
this processor's left and right neighbors for communication inside the iteration loop.
It's more efficient to calculate the neighbor id's outside the iteration loop.
- MPI_Irecv, MPI_Send, and MPI_Wait -
These elemental MPI calls perform the communication linking the trailing edge of one processor's data with the leading edge of the next processor's data.
leftIDProc and rightIDProc identify to and from which processors the messages are sent and received.
iterationloop is given an array one element larger than the space for which this processor is actually responsible.
The extra element is used as a "guard" element.
This guard element holds a duplicate of the closest element in the neighboring partition, making
it possible to reuse addleft and addright without modification.
At first the guard element is on the right edge of the partition. After addleft,
this processor's leftmost element is supplied to the left processor via an MPI_Send,
and this processor's rightmost element is filled in from the right processor via MPI_Irecv.
After addright, this processor's rightmost element is sent to the neighboring processor
on the right using MPI_Send while this processor's leftmost element is
filled using an MPI_Irecv that receives a message from the neighboring processor on the left.
MPI_Irecv specifies from what processor to expect the message and
where the message is to be written when it arrives from that other processor, but the message pass
is (most likely) not yet complete. Control is returned to the caller immediately (hence the "I"), allowing the caller
to do other work while the message is being handled. This behavior is called asynchronous message passing.
If we had called MPI_Recv here, this code would deadlock because every processor would wait on
a receive because no processor has sent a message.
We choose to use MPI_Irecv instead of MPI_Recv because we want to send a message to another
processor at the same time as we are receiving a message from another. Because we know that every other processor is doing the same thing with its neighbors,
it's wise to make it possible for our neighbor to complete its send of the message while this processor is itself
sending a message. This processor then calls MPI_Wait, passing the request structure produced by
the last MPI_Irecv, to wait for the recieve to complete.
One should always confirm that asynchronous messages complete using MPI_Wait or its relative, MPI_Test.
- arraySize and the malloc -
produces the memory allocation for each processor.
Every processor allocates enough memory to represent its partition of the problem space plus one extra element, the "guard" element,
of the neighboring processor's space.
Processor 0 must later hold the end result of the work of every processor to save the data later,
hence the
binomialExponent+nproc in that case.
- myArray[(binomialExponent>>1)-idproc*(arraySize-1)]=1; -
this line creates the seed, or initial conditions, for the system.
It calculates the position of the default seed, accounting for the distance between the leading edge of
this processor's partition from the leading edge of the entire system.
The prior if statement limits this seed to the relevant processor.
- MPI_COMM_WORLD -
MPI defines communicator worlds or communicators that define a set of processors that can communicate with each other.
At initialization, one communicator, MPI_COMM_WORLD, covers all the processors in the system. Other MPI calls
can define arbitrary subsets of MPI_COMM_WORLD, making it possible to confine a code to a particular processor subset
just by passing it the appropriate communicator.
In simpler cases such as this, using MPI_COMM_WORLD is sufficient.
- MPI_Gather -
fills myArray of processor 0 with the data in myArray from the other processors in preparation for
saving into one data file. myArray, arraySize-1, and MPI_LONG specify the first element, size (without the "guard" element),
and data type of the array.
0 specifies where the data is to be collected.
This call can be considered a "convenience" routine that simplifies the process of "gathering" regularly organized data from
other processors.
- ppinit -
performs initialization of the parallel computing environment.
Part of the boilerplate for MPI codes, this routine calls:
- MPI_Init - performs the actual initialization of MPI. It returns the error code; zero means no error.
- MPI_Comm_size - accesses the processor count of the parallel system
- MPI_Comm_rank - accesses the identification number of this particular processor
- ppexit - calling MPI_Finalize terminates
the parallel computing environment. Also part of the boilerplate of MPI codes, a call to
MPI_Finalize is needed to properly cleanup and close the connections between codes running on other
processors and release control. The call to
MPI_Barrier is optional, included here so that when all processors end up waiting for the user at processor 0 to
press the return key.
- __MWERKS__ -
these #ifdef blocks merely compensate for a pecularity about the Metrowerks CodeWarrior compiler.
These blocks allows the executable on other processors terminate automatically.
If you are using another compiler, you don't have to worry about this code.
Note that the routines that perform the actual propagation computation, addleft and addright,
did not need to be altered at all.
That was possible because
they were supplied just enough of the problem space to fulfill each processor's responsibility.
iterationloop maintained the interaction between processors, and
computeloop delegated the work between processors.
main's changes merely perform the boilerplate work of setting up and tearing down the
parallel environment, plus an if statement so only processor 0 writes the output file.
When this code, with its BinomialExponent constant set to 30 and the default seed,
is run in parallel on three processors, the code produces this output:
|
Processor 0 output
|
Processor 1 output
|
Processor 2 output
|
I'm processor #0 in a 3-processor cluster.
Beginning computation...
*
*
*
**
*
**
* *
****
*
**
* *
****
* *
** **
* * * *
********
* *
** *
* * *
**** **
* * *
** ** **
* * * * * *
writing array...
1 30 435 4060 27405 142506 593775 2035800 5852925 1430715030045015 54627300 86493225 119759850 145422675 155117520 145422675 119759850 86493225 54627300 30045015 14307150 5852925 2035800 593775 142506 27405 4060 435 30 1
press return to continue
|
|
I'm processor #1 in a 3-processor cluster.
Beginning computation...
**
* *
****
* *
** **
* * * *
********
* *
** **
* * *
*** ****
* * *
** ** **
* * * * * *
************
*
*
*
**
* *
* ***
* *
** **
* * *
*** ****
* * *
** ** **
* * * * * *
54627300 86493225 119759850 145422675 155117520 145422675 119759850 86493225 54627300 30045015 14307150 5852925 3260635 0 3274144 65537 65537 3275248 0 0 3275008 19941936 0 0 65537 3275280 0 0 327500819941936 0
|
|
I'm processor #2 in a 3-processor cluster.
Beginning computation...
*
*
**
*
**
* *
****
*
* **
* * *
******
*
**
* *
****
* *
* ** **
* * * * * *
5852925 2035800 593775 142506 27405 4060 435 30 1 0 01 3260635 0 3274144 65537 65537 3275248 0 0 327500819941936 0 0 65537 3275280 0 0 3275008 19941936 0
|
|
The Sierpinski gasket is visible, but sliced into three parts, a consequence of the partitioning of the problem space
between these three processors.
As intended, the trailing edge of one partition is repeated in the leading edge of the next.
It is very important to realize that no one processor ever has a complete picture of the problem: each processor has information only about its own space.
At the end of the code, all processors print the data they have,
but only processor 0 has the complete answer due to the MPI_Gather call.
Clearly compartmentalizing the code structure into the routines that are responsible for
interprocessor communication from those responsible for
computation
makes it much easier to debug, modify, and upgrade portions of the code.
Consequently, this code can easily benefit from exploiting the "orthogonality" of parallelization and
vectorizing.
The addright and addleft routines are unaffected by the
parallelization, so it would be straightforward to vectorize their code.
Listing 3 - a vectorized alternative to the above addleft routine
void addleft(myType *inputArray, long size)
{
if (inputArray) {/*compensate for misaligned reads and writes*/
long i, vectorLoop=(size-1)>>2;
vector myType lastElement=vec_ld(0, inputArray);
vector unsigned char perm0=vec_lvsl(0, inputArray),
perm1=vec_lvsl(sizeof(myType), inputArray),
permOut=vec_lvsr(0, inputArray);
vector myType lastOut=vec_perm(lastElement, lastElement, perm0);
for(i=0; i<vectorLoop; i++) {
vector myType element=vec_ld((i<<4)+16, inputArray), out;
out=vec_add(vec_perm(lastElement, element, perm0),
vec_perm(lastElement, element, perm1));
lastElement = element;
vec_st(vec_perm(lastOut, out, permOut), i<<4, inputArray);
lastOut=out;
}
for(i=(vectorLoop<<2); i<size-1; i++)
inputArray[i]+=inputArray[i+1];
}
}
|
|
We suggest vectorizing addright
as an exercise for the reader.
The purpose of this discussion was to most clearly highlight what changes are needed
to parallelize a application whose problem has inherent local interactions.
We chose a simple problem of this category so attention could be drawn to the parallelization.
Components of your code may
correspond to the routines in pascalstriangle, so this parallelization example could suggest how to parallelize your code.
This example can be a starting point
to experiment with parallel computing.
For example, one could try modifying the above parallel code with
different seed rows, or introduce seeds at a later point in the computation.
One could display interim steps in the simulation using a display more complex than asterisks, including a
complete GUI.
Although the propagation rule would probably have to change, the problem space could be extrapolated
to greater than one dimension.
Different propagation rules could be applied, including ones that would require more guard elements between partitions.
One could even make this code interactive, allowing a user or users to click on where new seeds would dynamically be
introduced.
These fancier features are not shown here because they would distract from the purpose of this discussion,
but the reader is welcome to explore the possibilities.
References
Using MPI by William Gropp, Ewing Lusk and Anthony Skjellum
is a good reference for the MPI library. Many of the techniques and
style of the above parallel code were adopted from Dr. Viktor K. Decyk.
He expresses these ideas in a few references, including:
- V. K. Decyk, "How to Write (Nearly) Portable Fortran Programs for Parallel Computers", Computers In Physics,
7, p. 418 (1993).
- V. K. Decyk, "Skeleton PIC Codes for Parallel Computers", Computer Physics Communications,
87, p. 87 (1995).
You're welcome to read more about parallel computing
via the Tutorials page.
|
