|
Parallelization - Parallel Knock
|
We describe a simple example of message passing in a parallel code.
For those you learning about parallel code,
we provide the following discussion of elemental message-passing
as an introduction to how communication can be performed in parallel codes.
|
Knock
This example, knock.c,
passes a simple message from the even processors to the odd ones.
Then, the odd processors send a reply in a message back to the even ones.
The "conversation" is displayed on all processors, and the code ends.
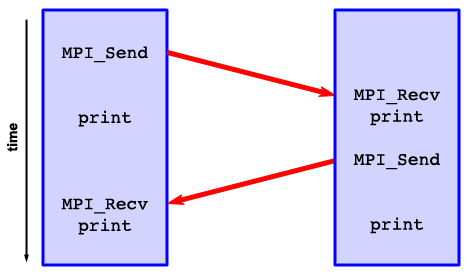
This code's main routine performs the appropriate message-passing calls.
In a more complex parallel code, these can be used to pass information processors to coordinate or complete useful work.
Here, we focus on the basic technique to pass these messages.
The C source is shown in Listing 1.
Listing 1 - knock.c, or see knock.f
#include <stdlib.h>
#include <stdio.h>
int main(int argc, char *argv[])
{
/*
this program demonstrates a very simple MPI program illustrating
communication between two nodes. Node 0 sends a message consisting
of 3 integers to node 1. Upon receipt, node 1 replies with another
message consisting of 3 integers.
*/
/* get definition of MPI constants */
#include "mpi.h"
/* define variables
ierror = error indicator
nproc = number of processors participating
idproc = each processor's id number (0 <= idproc < nproc)
len = length of message (in words)
tag = message tag, used to distinguish between messages */
int ierror, nproc, idproc, len=3, tag=1;
/* status = status array returned by MPI_Recv */
MPI_Status status;
/* sendmsg = message being sent */
/* recvmsg = message being received */
/* replymsg = reply message being sent */
int recvmsg[3];
int sendmsg[3] = {1802399587,1798073198,1868786465};
int replymsg[3] = {2003332903,1931506792,1701995839};
printf("Knock program initializing...\n");
/* initialize the MPI execution environment */
ierror = MPI_Init(&argc, &argv);
/* stop if MPI could not be initialized */
if (ierror)
exit(1);
/* determine nproc, number of participating processors */
ierror = MPI_Comm_size(MPI_COMM_WORLD,&nproc);
/* determine idproc, the processor's id */
ierror = MPI_Comm_rank(MPI_COMM_WORLD,&idproc);
/* use only even number of processors */
nproc = 2*(nproc/2);
if (idproc < nproc) {
/* even processor sends and prints message,
then receives and prints reply */
if (idproc%2==0) {
ierror = MPI_Send(&sendmsg,len,MPI_INT,idproc+1,tag,
MPI_COMM_WORLD);
printf("proc %d sent: %.12s\n",idproc,sendmsg);
ierror = MPI_Recv(&recvmsg,len,MPI_INT,idproc+1,tag+1,
MPI_COMM_WORLD,&status);
printf("proc %d received: %.12s\n",idproc,recvmsg);
}
/* odd processor receives and prints message,
then sends reply and prints it */
else {
ierror = MPI_Recv(&recvmsg,len,MPI_INT,idproc-1,tag,
MPI_COMM_WORLD,&status);
printf("proc %d received: %.12s\n",idproc,recvmsg);
ierror = MPI_Send(&replymsg,len,MPI_INT,idproc-1,tag+1,
MPI_COMM_WORLD);
printf("proc %d sent: %.12s\n",idproc,replymsg);
}
}
/* terminate MPI execution environment */
ierror = MPI_Finalize();
if (idproc < nproc) {
printf("hit carriage return to continue\n");
getchar();
}
return 0;
}
|
|
Discussing the parallel aspects of this code:
- mpi.h - the header file for the MPI library, required to access information about the parallel system and perform communication
- idproc, nproc -
nproc describes how many processors are currently running this job and
idproc identifies the designation, labeled using integers from 0 to nproc - 1, of this processor.
This information is sufficient to identify exactly which part of the problem this instance of the executable should work on.
- MPI_Init - performs the actual initialization of MPI, setting up the connections between processors for any
subsequent message passing. It returns an error code; zero means no error.
- MPI_COMM_WORLD -
MPI defines communicator worlds or communicators that define a set of processors that can communicate with each other.
At initialization, one communicator, MPI_COMM_WORLD, covers all the processors in the system. Other MPI calls
can define arbitrary subsets of MPI_COMM_WORLD, making it possible to confine a code to a particular processor subset
just by passing it the appropriate communicator.
In simple cases such as this, using MPI_COMM_WORLD is sufficient.
- MPI_Comm_size - accesses the processor count of the parallel system
- MPI_Comm_rank - accesses the identification number of this particular processor
- if (idproc%2==0) - Up until this line, the execution of main by each processor has been the same.
However, idproc distinguishes each processor. We can take advantage of this difference by
guiding the processor to a different execution as a function of idproc. This Boolean statement
causes those processors whose idproc is even (0, 2, 4, ...) to execute the one part of the if-block, while the
odd processors (1, 3, 5, ...) execute the second part of the block.
At this point, no central authority is consulted for assignments; each processor recognizes what part of the problem it should perform
using only its idproc.
- MPI_Recv and MPI_Send -
These elemental MPI calls perform communication between processors.
In this case, the even processor, executing the first block of the if statement,
begins by using MPI_Send to send the contents of the sendmsg array,
whose size is given as 3 long integers, specified by len and MPI_INT,
to the next processor, specified by idproc+1.
tag merely identifies the message for debugging purposes, and must match the tag on the corresponding receive.
MPI_Send returns when the MPI library no longer requires that block of memory, allowing your code to
execute, but the message may or may not have arrived at its destination yet.
Meanwhile, the odd processor uses MPI_Recv to receive the data from the even processor at idproc-1.
This processor specifies that the message be written to recvmsg. The call returns information
about the message in the status variable.
MPI_Recv returns when it is finished with the recvmsg array.
Note that the even and odd processors might not be in lock step with one another.
Such tight control is not needed to complete this task.
One processor could reach one MPI call sooner than the
other, but the MPI library performs the necessary coordination so that the message is properly handled while allowing each processor to
continue with work as soon as possible.
The processors affect one another only when the communicate.
After printing the first message, each processor switches roles.
Now the odd processors call MPI_Send to send back a reply in replymsg,
and the even processors call MPI_Recv to receive the odd processors' reply in their recvmsg.
For debugging, the tag used is incremented on all processors.
Note that this is a distributed-memory model, so the instance of recvmsg on one processor resides in
the memory on one machine while the other instance of recvmsg resides on a completely different piece of hardware.
Here we are using the even processors' recvmsg for the first time
while the odd processors' recvmsg
holds data from the first message.
Finally, each processor prints this second message.
- MPI_Finalize - performs the properly cleanup and close the connections between codes running on other
processors and release control.
When this code, with the initialization values in sendmsg and replymsg,
is run in parallel on two processors, the code produces this output:
|
Processor 0 output
|
Processor 1 output
|
Knock program initializing...
proc 0 sent: knock,knock!
proc 0 received: who's there?
hit carriage return to continue
|
|
Knock program initializing...
proc 1 received: knock,knock!
proc 1 sent: who's there?
hit carriage return to continue
|
|
It performs the opening lines of the classic "knock, knock" joke.
This example is an appropriate introduction because that joke requires
the first message to be sent one way, then the next message the other way.
After each message pass, all processors print the data they have
showing how the conversation is unfolding.
The MacMPI tutorial shows a visualization of this message passing.
Conclusion
The purpose of this discussion was to highlight the basic techniques needed to
perform elemental message passing between processors.
It also shows how one identification number, idproc, can be used to cause different behavior
by distinguishing between processors.
The overhead of initialization (MPI_Init et al) and
shut down (MPI_Finalize) seems large compared to the
actual message passing (MPI_Send and MPI_Recv) only because the nature of the message passing is so simple.
In a real-world parallel code, the message-passing calls can be much more complex and interwoven with execution code.
We chose a simple example so attention could be drawn to the communications calls.
The reader is welcome to explore how to integrate these calls into their own code.
References
knock.c and knock.f were written by Dr. Viktor K. Decyk of the UCLA Department of Physics and is
reproduced here with permission.
Using MPI by William Gropp, Ewing Lusk and Anthony Skjellum
is a good reference for the MPI library.
Dr. Decyk also expresses other examples of parallel comuputing in a few references, including:
- V. K. Decyk, "How to Write (Nearly) Portable Fortran Programs for Parallel Computers", Computers In Physics,
7, p. 418 (1993).
- V. K. Decyk, "Skeleton PIC Codes for Parallel Computers", Computer Physics Communications,
87, p. 87 (1995).
You're welcome to read more about parallel computing
via the Tutorials page.
|
