|
128 Xserve G5 Cluster Running the AltiVec Fractal Benchmark
Xserve cluster achieves 1.21 TeraFlop using 256 2-GHz G5's and
demonstrates excellent potential scalability
Hardware:
| Nodes: |
128 Dual-Processor Xserve G5/2GHz's |
| Network: |
Cisco 6500 Series Gigabit Switch
|
Software:
Name:
Prime User and Purchaser:
Location and Management:
Date:
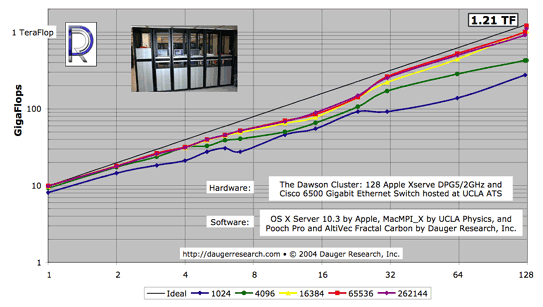
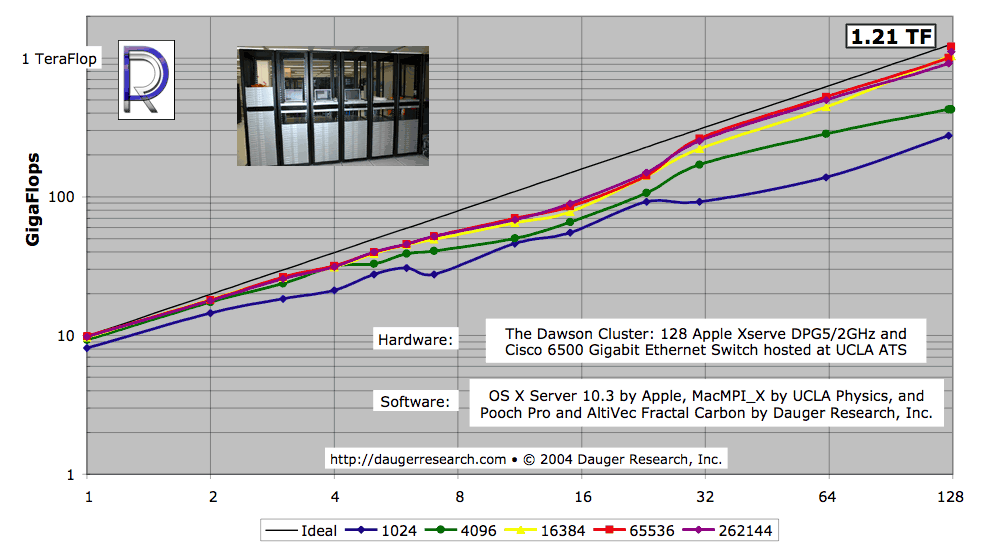
The above figure illustrates the potential performance and scalability of clusters
using Apple's new
Xserve G5.
The UCLA Plasma Physics Group Group
recently acquired and assembled a cluster using 128 Xserve G5s.
Using Pooch Pro,
the group ran the
AltiVec Fractal Carbon benchmark
and achieved 1.21 trillion floating-point operations per second on this Xserve cluster.
(This result is similar to that using Linpack, placing the Dawson cluster in
the most recent Top 500 Supercomputer List.)
The Plasma Physics Group has extensive experience using other parallel computer and cluster types.
This cluster, named in honor of the late Professor John M. Dawson, is in active use for plasma physics projects
at UCLA and other projects in collaboration with the Stanford Linear Accelerator (SLAC).
UCLA's Academic Technology Services manages, houses, and provides facilities for the Dawson cluster.
Both
MacMPI
and
LAM/MPI are used on this cluster.
As of this writing, this is the largest, most powerful Xserve cluster built for physical science known to exist in academia.
Applications
The Dawson cluster is in active use for plasma physics research.
Its primary applications are particle-based "Particle-In-Cell" (PIC) plasma codes:
- QuickPIC - a 3-D parallel quasi-static PIC code originally developed for
plasma wakefield accelerator research being used for beam plasma interactions
by Warren Mori and his team
- osiris -
a three-dimensional electromagnetic PIC code used to
model plasma beam instabilities
in the Stanford Linear Accelerator
- P3arsec - a three-dimensional fully electromagnetic PIC code written by
John Tonge as part of his doctoral work,
used to investigate plasma confinement, Alfvén waves (see
George Morales), and other topics
- Quantum PIC -
a code that utilizes classical paths to time-evolve interacting quantum wavefunctions
based on
Dean Dauger's doctoral work
- Numerical Tokomak project - a suite of three-dimensional gyrokinetic PIC codes used to model
large plasma confinement devices for fusion science by
Jean-Noel Leboeuf
and Rick Sydora
- UCLA Parallel PIC - a framework of
object-oriented components for the rapid
constructions of new parallel PIC codes, written by
Viktor Decyk
These are parallel Fortran and Fortran 90 codes using
MPI for portable message-passing.
About the Benchmark
The different colored lines indicate the fractal benchmark code operating on different
problem sizes. As expected on any parallel computer running a particular problem type,
larger problems scale better.
The AltiVec Fractal Carbon demo
uses fractal computations that are iterative in nature.
For a portion of the fractal image, these iterations
may continue ad infinitum; therefore, a maximum iteration count is imposed.
In the AltiVec Fractal Carbon demo, this limit is specified using the Maximum Count setting.
Increasing the Maximum Count setting to 16384, then 65536, and so on,
increases the problem size.
It was clear that, given sufficient problem size, the Xserve G5 cluster was
able to acheive over a TeraFlop
(1 TF = 1000 GF = one trillion floating-point calculations per second).
The performance is determined by the total number of floating-point calculations
performed that contribute to the answer and the time it takes to construct the answer.
This time includes not
only the time it takes to complete the computation, but also the time it takes to
communicate the results to the screen on node 0 for the user to see. Also note that
we quote the actual achieved performance, a practical measure of
true performance while solving a problem, rather than the theoretical peak performance.
The time it takes to compute most of these fractals is roughly proportional
to the Maximum Count setting, yet, since the number of pixels is the same, the
communications time remains constant. For the smallest problem sizes on
a large number of nodes, it was
clear that communications time became greater than the computation time. By increasing
the problem size significantly, the computation time was once again much greater than
the communications time.
The dark "Ideal" line is an extrapolation multiplying the node count by
the performance of one node alone. As shown in the graph, the cluster's performance
while solving the larger problems
closely approach that "Ideal" extrapolation.
That observation tells us we can find no evidence of an intrinsic limit to the size of a Mac cluster.
Conclusion
After running a series of numerically-intensive trials on a 128-node Xserve G5
cluster, we were able to achieve over a TeraFlop on certain problems. These
results were repeatable.
No evidence of an intrinsic limit to the size of a Macintosh-based cluster could be found.
Building on previous results
using 76 Dual-Processor Power Macs at USC and
using 33 Dual-Processor Xserve G4s at NASA's JPL,
this finding
confirms that Macintosh-based clusters are capable of excellent scalability in performance.
Acknowledgements
The above could not be accomplished without involvement of many people.
Many thanks goes to UCLA's
Plasma Physics Group
and
Academic Technology Services.
We also thank Tim Parker and Skip Cicchetti
from Apple Computer, Inc.,
for faciliating the purchase of and providing direct assistance with the cluster.
| 
{kind=link}