| Dauger Research Vault | ||
| Tutorial | ||||||||||||||||||||||
|
||||||||||||||||||||||
|
Parallel Zoology
Communication for Computing's Sake
When one thinks about computing the solution to a numerical problem, one usually focuses on the mathematical steps, but the steps that are often overlooked are the steps to transfer and rearrange, or communicate, data that are just as essential to computing the solution. Numerical solutions can be broken down into steps, and some of these steps are mathematical operations (addition, subtraction, multiplication, etc.), some are logical operations (determining true or false, if-then-else), and some of these are communcation operations. All these steps are essential to accomplishing the task at hand. The relative amount of communication and other operations in a solution depend greatly on which problem is being solved. Therefore, even for problems with equal numbers of mathematical operations, certain problems will require more data transfer or communication than others. These characteristics determine what resources are necessary to solve such problems. Communication in Non-Parallel Computation Consider the most recent advances in personal computers. Processor speeds are continuing to climb. We have seen MHz make way for GHz, and MegaFlops (millions of floating-point operations per second or "flops") give way to GigaFlops (billions of flops). Yet participants of the computer industry have come to realize that the speed at which the memory or the system bus or the video card moves data around is also very important to the overall performance of the computer. For example, the Power Mac G5 performs so much better than the prior G4 systems not only because of the PowerPC G5, but because of all the work its designers poured into improving the system bus, memory, and I/O (input/output) subsystems. Those designers clearly recognized that efficiently performing operations as seemingly trivial as moving data around was important to the overall performance of the machine. The Apple hardware team did the right thing when they overhauled these subsystems, resulting in perhaps the best-designed personal computer in existence. Of course, not all applications require such well-performing system buses. The fastest typist in the world can maintain 150 words per minute using a standard keyboard. This means a computer word processor should only require an average bandwidth of roughly 25 bytes per second. Clearly computer designers are motivated to improve system speed for problems such as video editing and other problems processing gigabytes of data, rather than for word processing. It's not that word processing is any less valuable than other problems. They recognize that different computations have different demands, so they try to design for the more difficult problems that the computational hardware may encounter. Likewise, we design cluster solutions that address the more challenging problems, addressing the less challenging ones automatically. Communication for Parallel Computation As it is for computing with a single processor, parallel computation relies on both computation and communication to solve numerical problems. A parallel computer's hardware and software design and implementation determines how well it will perform such operations. In the case of a parallel computer composed of interconnected personal computers, how well it uses its network determines its effective communications performance.
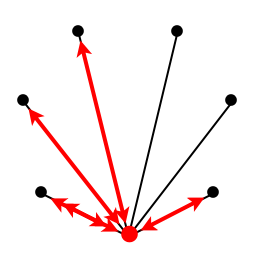
In many ways, distributed computing, which performs computations on many machines connected over the Internet, is an extreme example of grid computing. RSA key breaking and SETI@Home are excellent examples of problems that can use distributed and grid computing solutions because their communications need is so low. A central server assigns portions of the problem to machines on the Internet. The node works on its assignment for hours or even days, then replies with a single bit expressing if it found the answer (the key or the signal, respectively) or not. In the most common case, false, the node receives another assignment. This infrequent communication, as little as once every few days, is what makes it possible to implement over the Internet. Very few problems fit this solution, but for key breaking and SETI and similar problems, it is the right tool for the job.
By designing for the worst case, clusters and supercomputers are suitable for this more difficult parallel codes, but they can easily accommodate grid and distributed computing just as well. Just like how the Power Mac G5 can handle both video editing and word processing because it was designed for the more computationally difficult problem, clusters and supercomputing can handle these more difficult parallel problems and the problems that function in grid and distributed computing. In other words, cluster computing performs a superset of what grid computing can do. Parallel Spreadsheet
Each employee can work on their portion of the spreadsheet, but they will soon encounter a new problem. Employee 1 needs some data from employee 6's spreadsheet section in order to compute the following quarter's data from the previous. Then employee 2 might need data from columns just outside her partition, which employees 1 and 3 both have. Soon, no employee is able to perform the calculation because the data they need is elsewhere.
So far, this is the scenario that could occur with distributed and grid computing if you attempted to solve certain kinds of challenging computing problems. If we knew in advance that the communication these employees needed was very low, for example, if every spreadsheet cell only needed the cell on the preceding row, then there would be no problem with using only the centralized phone network. But in the general case we cannot guarantee that the problem will conform to the design of a limited tool.
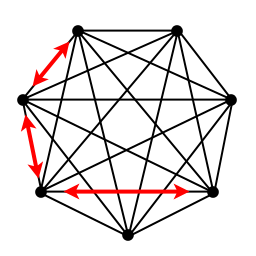
A switched networking fabric, such as an Ethernet switch, is the computer hardware equivalent of the above upgraded telephone network. However, that hardware alone is not sufficient. Distributed and grid implementations do not support this switched kind of communication between nodes. Using the above analogy, it would be as if the employees don't know each others' phone numbers and only know the manager's phone number. The software implementation needs to support use of the switching system. Clusters and supercomputers do support full use of switched communications such as direct node-to-node communication, most often using Message-Passing Interface (MPI). Like the manager setting up the phone system and telling the employees in advance what each others' phone numbers are, the cluster or supercomputer support software initializes the network connections and supplies the compute nodes with each others' network addresses. The Need to Communicate Different problems require different amounts of communication to complete their work. The late Dr. Seymour Cray, creator of the earliest machines to become publicly known as "supercomputers", designed his memory systems to provide data as fast as his processors could use them. Unfortunately, by the end of the 1980s, the expense of maintaining equity between memory and processor speed became prohibitive. In the 1990s, elaborate caching schemes became the common way to compensate for the disparity between memory and processor speed. Their effectiveness depended heavily on the application. The applications run on a parallel computers today vary widely. They could be data mining, Monte Carlo calculations, data processing, large scientific simulations, or 3D rendering. Each application requires a different amount of communication for a given number of mathematical operations they perform. Minimizing the time spent communicating is important, but the time and effort spent by the developers of these codes has revealed that certain problems must exchange a minimum amount of data to perform their computation. Dr. Cray addressed this ratio between data access, or communication, and mathematical computation when designing his supercomputers. Although he was focused on low-level processor and memory design, we can also apply this criterion to parallel computers. A parallel application performs communication between nodes in order to complete computations inside these nodes (much like how the employees in the above example needed to phone each other to complete the spreadsheet). We can categorize applications of parallel computing by this ratio. For example, the analyzing data in a SETI@Home assignment can take days to perform, while the data size of the assignment is about 900 kB. 900 kB per day is an average bandwidth of about 10 bytes per second. The calculation probably achieves roughly 500 MegaFlops per node, so the communications to computation ratio would be about 10 bytes/500 million flops = 0.02 bytes/MF. On the other hand, plasma particle-in-cell (PIC) codes perform hundreds of MegaFlops per node, yet require 1 to 15 MegaBytes/second of communication from one node to any other, depending on the nature of the plasma being simulated. So the communications to computation ratio can range from 2 to 20 bytes/MF in the most typical cases. 20 bytes/MF is a far cry from the internal bandwidth to flops ratio a modern computer is capable of, but the plasma code has been optimized to take full advantage of a node's capabilities while taxing the network the least. Its developers are motivated to do so to take best advantage of supercomputing hardware. The time and effort spent optimizing such codes has revealed a communications requirement that appears to be intrinsic to the nature of the problem. Considering this communications requirement illustrates why SETI@Home can be implemented across the Internet, while a large plasma PIC simulation cannot. Multiply SETI@Home's 10 bytes/second/node requirement by a million nodes, and you get about 10 MB/sec. Any well-connected web server can easily supply that bandwidth, and the distribution system of the Internet naturally divides this data stream into smaller and smaller tributaries. Bear in mind that the problem requires a large pipe only on the central server. A plasma code requires many MB/sec between any two nodes and in each direction. The bandwidth typically achieved between any two nodes of the Internet is a few orders of magnitude short. Even good broadband connections upload at about 0.1 MB/sec. And, as anyone browsing the web knows, the response time (or latency) can be unreliable, exacerbating the communication issue. Inspired by the above comparison, one can therefore estimate and compare the communications to computation ratios of other applications of interest, obtaining a rough idea of how various calculations compare. Varying the parameters can can change the communications demands for each problem type, making them require a range of communication to computation ratios.
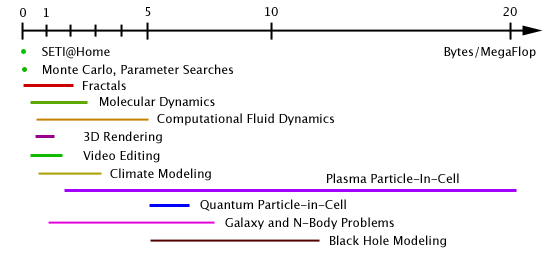
Laying out different problems this way shows that the demands of parallel applications lie along a wide spectrum. A few numbers will never completely characterize a calculation, but there are some basic ideas that we can deduce from this evaluation. Some problems require a very low amount of communication for the computation performed. Those problems can be efficiently solved on distributed and grid computing architectures. Those with higher communications to computation ratios are more demanding of the available bandwidth. Many of these are known as "tightly coupled" problems. Clusters and supercomputers can handle these more demanding problems, but could also easily handle the problems that grid computing is limited to. Different parallel computing solutions have different capabilities, and these capabilities determine what kinds of problems these machines can solve. These machines can perform a maxmimum number of floating-point operations and send an aggregate amount of data between nodes simultaneously. These characteristics can be plotted on a two-dimensional graph, where different solutions will cover different regions of capability.
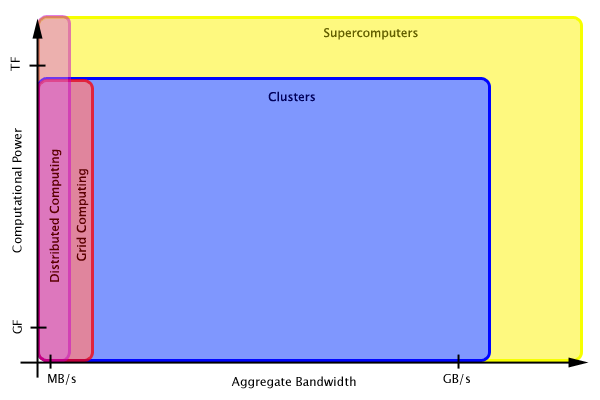
On the above graph we plot the range of problem sizes that various types of parallel computers can address, from distributed to grid to cluster to supercomputer. Each type can perform a maximum number of floating-point operations and communicate a maximum amount of data at any one time. Because of their centralized control and data access, distributed and grid computing are limited to the bandwidth of the pipe at that centralized control machine. However, clusters and supercomputers can communicate from any node to another in numerous simultaneous streams. A well-designed parallel application would take full advantage of that property of clusters and supercomputers. Therefore, their aggregate bandwidth, assuming the network is homogenous, is proportional to the number of nodes and network bandwidth of each node. Note that grid computing's capabilities are a subset of cluster computing, and likewise for distributed computing and supercomputing. The largest number of floating-point operations distributed computing can operate is limited only by the number and performance of the nodes users contribute to the task across the Internet. Grids and clusters are limited to the number of nodes they can utilize at once, typically a local collection of networked computers. The difference is that clusters are designed to utilize all network connections between nodes, supporting all known parallel computing types within the limits of the hardware. Supercomputers have the best available hardware and networking combined in one machine, so of course they can do everything the other parallel computing types types can do. Of course, as computing hardware improves, all of these boundaries will ever expand to larger and larger problems, but the relative regions should remain similar. We can use this format to illustrate the differences between parallel applications to see how they fit with the available parallel computing solutions. We can incorporate the problem size, in terms of both number of mathematical operations and aggregate bandwidth, required to perform the calculation. The number of floating-point operations necessary to complete the calculation is relevant, as is the aggregate bandwidth, that is, the total amount of data sent or received between the compute nodes due to the calculation. These characteristics can be plotted on the same two-dimensional graph. A problem spreads across the graph along a line whose slope is roughly the bytes/MF ratio introduced above. The exact region a parallel application occupies depends on the problem.
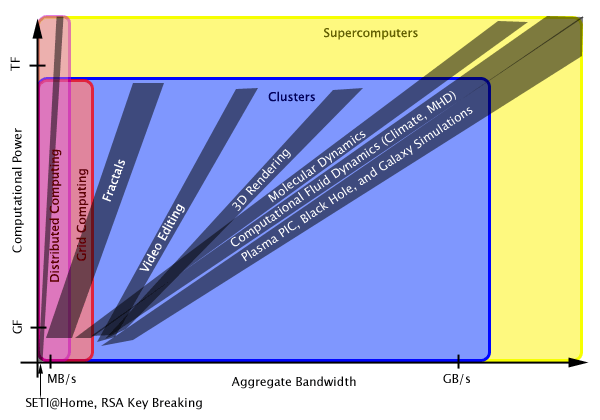
As we can see, a number of interesting problems fall in the regions covered by clusters and supercomputers that are not well addressed by distributed and grid computing. Significant problems such as SETI@Home and key breaking. Of course, a cluster is often formed using fewer than resources than those available to supercomputing centers, so clusters cannot address everything a supercomputer can, but a wide spectrum of interesting problems are appropriate for clusters. Choose Your Tool Dr. Keiji Tani of the Global Scientific Information and Computing Center in Japan gave a talk at the IEEE Cluster 2002 conference in Chicago soon after their Earth Simulator was rated the most powerful supercomputer in the world. He saw the commotion in the U. S. that the Earth Simulator was causing about displacing the former supercomputing record holder. In his talk he was trying to emphasize the fact that tools are meant to be used for the problems they were designed to solve, saying "There's a place for everything." No one computer system or design is "the best" in a universal sense. His message was the "best" computer is the one that accomplishes your task and solves your problem best. Understanding the nature of one's computational problem helps determine the most efficient methods and tools needed to solve it. For parallel computing, it is important to recognize how to organize both the computation and communication necessary to run the application. The above gives an idea of how to characterize and evaluate such issues. While some important calculations can be performed on distributed and grid computing solutions, that is often not enough. At the same time, a cluster generally can perform, besides everything a grid computing solution can accomplish, a large set of calculations that supercomputers can address. We design clusters that address these more challenging problems.
For Additional Reading
You're welcome to read more about parallel computing via the Tutorials page.
|
||||||||||||||||||||||

| Pooch is a trademark of Dauger Research Macintosh and Mac OS are trademarks of Apple Computer |